

当一个同事问我:Java中的double的取值范围是多少时,我一脸的茫然,除了知道浮点数由符号位、指数位和小数位组成之外,其它的一无所知。大学里《计算机组成》中学的东西也忘得一干二净。
查了一些资料,并亲手写了些测试代码,总算弄明白了,在此做个笔记。
1.三种存储格式
Java遵循的是IEEE 754 规范。在这个规范里,提到了浮点数的三种类型:单精度、双精度和双精度扩展。
这三种类型的浮点数的存储都由三部分组成:符号位、指数位和小数位组成,不同的是三者指数位和小数位的位数不一样。
IEEE 单精度格式具有24 位有效数字精度,并总共占用32 位。IEEE 双精度格式具有53 位有效数字精度,并总共占用64 位。至于双精度扩展,IEEE规定它至少具有64 位有效数字精度,并总共占用至少79 位。
2.双精度格式
现在,我们仅仅对双精度浮点数,也就是double进行分析,其它的两种可以此类推,不必赘述。
IEEE 双精度格式由三部分组成:52位小数f ;11 位偏置指数e ;以及1 位符号s。
这些字段连续存储在两个32 位字中。如下图所示:

将这两个连续的32 位字按一个64 位字那样进行了编号,其中0:51 位存储52 位的小数f ; 52:62 位存储11 位偏置指数e ;而第63 位存储符号位s。
s为0表示整数,1则为负数。
e[52:62]总共11位表示偏置指数,也就是阶码部分。它是一个无符号数,取值范围是[0,2047]。当0
双精度存储格式位模式及其IEEE 值的位模式的对应关系可参见下表:
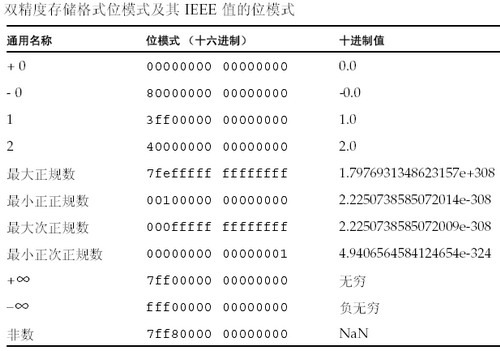
上图中的无意义数(NaN,非数)的位模式只是可表示NaN的众多位模式中的一种而已。另外,我们注意到,尽管+0和-0的十进制值是相等的,但它们的位模式却不一样。
3.代码示例
既然对存储格式已经了解清楚了,我们可以通过编写代码来验证其正确性,顺便加深对浮点数存储的理解。
Java中的类Double封装了double的操作,我们很容易通过Double来操作double. 函数Double.longBitsToDouble()可以把给定的位模式转换成double。如果要验证十六进制的0x7fefffffffffffff位模式是不是十进制的,这个很容易,只需要如下两行代码:
double value = Double.longBitsToDouble(0x7fefffffffffffffL);
System.out.println(value);
我们可以看到,输出结果是:
1.7976931348623157E308
这与我们期望中的也是吻合的。
其它的例子我就不逐一演示,这儿我附上代码的链接。<下载>
参考资料:
1.IEEE Standard 754 for Binary Floating-Point Arithmetic
2.Numerical Computation Guide(http://gceclub.sun.com.cn/TT/sunstudio/NCG/819-4817-10.pdf)
(完)
请你留言